公章遗失登报多少钱?公章遗失登报怎么办理?一文了解
2026/6/17 21:56:55
你的数据散落在三个地方:
每次做分析,你要手动从三个地方导出、拼接、去重。
如果这三个地方的数据能自动互相同步——你的工作就少了80%。
这篇文章讲的就是"数据跨平台同步"这件事。
跨平台数据同步,本质上是三个动作的循环:
读取源A → 转换格式 → 写入目标B所有同步方案都是这个结构的变体。
区别只在于:
这是最常见的同步场景——采集数据到Excel,需要入库持久化。
拼多多店群自动化报活动上架!
importpandasaspdimportsqlite3defexcel_to_sqlite(excel_path,db_path,table_name,mode='replace'):"""将Excel数据同步到SQLite"""df=pd.read_excel(excel_path)conn=sqlite3.connect(db_path)ifmode=='replace':df.to_sql(table_name,conn,if_exists='replace',index=False)elifmode=='append':df.to_sql(table_name,conn,if_exists='append',index=False)elifmode=='upsert':# 先建临时表,再用INSERT OR REPLACEdf.to_sql(f'{table_name}_tmp',conn,if_exists='replace',index=False)conn.execute(f'DELETE FROM{table_name}WHERE 日期 IN (SELECT 日期 FROM{table_name}_tmp)')conn.execute(f'INSERT INTO{table_name}SELECT * FROM{table_name}_tmp')conn.execute(f'DROP TABLE{table_name}_tmp')conn.commit()conn.close()print(f'同步完成:{len(df)}条 →{table_name}')defsqlite_to_excel(db_path,table_name,excel_path,query=None):"""将SQLite数据导出到Excel"""conn=sqlite3.connect(db_path)ifquery:df=pd.read_sql_query(query,conn)else:df=pd.read_sql_query(f'SELECT * FROM{table_name}',conn)df.to_excel(excel_path,index=False)conn.close()print(f'导出完成:{len(df)}条 →{excel_path}')全量同步简单但每次都重写整个表。数据多了以后很慢。
增量同步只处理新增和变更的数据:
defincremental_sync(excel_path,db_path,table_name,key_column='id'):"""增量同步:只同步Excel中新增和变更的记录"""df_new=pd.read_excel(excel_path)conn=sqlite3.connect(db_path)# 获取数据库中已有的ID集合existing_ids=set(pd.read_sql_query(f'SELECT{key_column}FROM{table_name}',conn)[key_column].values)# 分离新增和变更new_ids=set(df_new[key_column].values)to_insert=df_new[~df_new[key_column].isin(existing_ids)]to_update=df_new[df_new[key_column].isin(existing_ids)]# 插入新增to_insert.to_sql(table_name,conn,if_exists='append',index=False)# 更新已有(用temp table + update)iflen(to_update)>0:to_update.to_sql('_tmp_update',conn,if_exists='replace',index=False)# 构建UPDATE语句...(这里简化处理,实际按需写)conn.commit()conn.close()print(f'增量同步:新增{len(to_insert)},更新{len(to_update)}')importrequestsimportpandasaspddeffeishu_bitable_to_excel(app_token,table_id,token,excel_path):"""读取飞书多维表格并导出为Excel"""headers={"Authorization":f"Bearer{token}"}all_records=[]page_token=NonewhileTrue:url=f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records"params={"page_size":500}ifpage_token:params["page_token"]=page_token 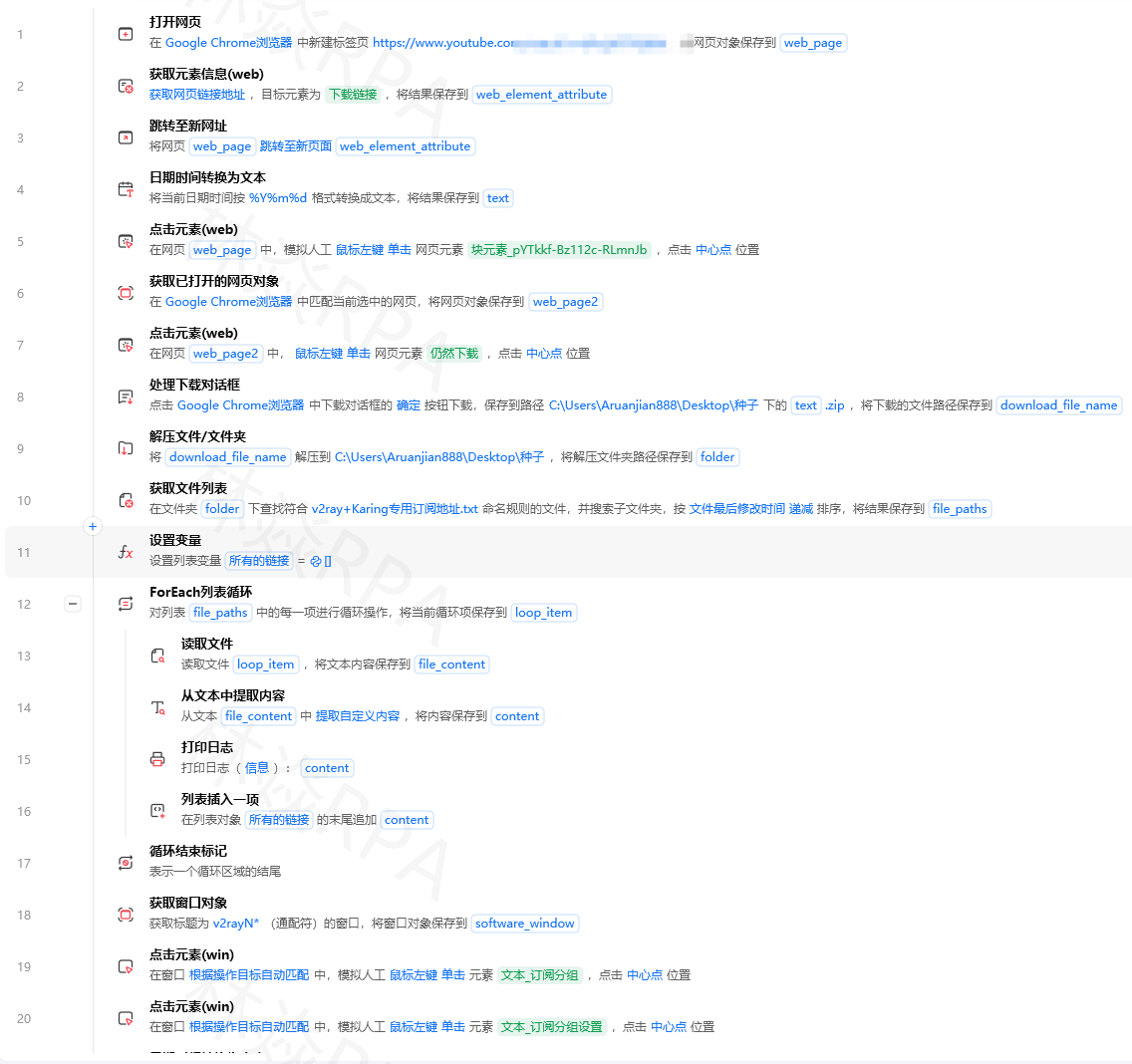resp=requests.get(url,headers=headers,params=params)data=resp.json()forrecordindata.get('data',{}).get('items',[]):all_records.append(record['fields'])ifnotdata.get('data',{}).get('has_more'):breakpage_token=data['data']['page_token']df=pd.DataFrame(all_records)df.to_excel(excel_path,index=False)print(f'飞书 → Excel:{len(df)}条')参考上一篇飞书文档的文章,用batch_create接口写入。
每天 08:00:飞书 → 本地SQLite(拉取最新线上数据) 每天 20:00:本地SQLite → 飞书(推送今日采集结果)避免同一时间双向同步——可能导致数据冲突。
简单但高频的场景。
df=pd.read_excel('data.xlsx')df.to_csv('data.csv',index=False,encoding='utf-8-sig')df=pd.read_csv('data.csv')df.to_excel('data.xlsx',index=False)importglobdefbatch_csv_to_excel(folder,output_folder=None):"""把一个文件夹里的所有CSV转成xlsx"""ifoutput_folderisNone:output_folder=folder csv_files=glob.glob(os.path.join(folder,'*.csv'))forcsv_fileincsv_files:df=pd.read_csv(csv_file)basename=os.path.splitext(os.path.basename(csv_file))[0]excel_path=os.path.join(output_folder,f'{basename}.xlsx')df.to_excel(excel_path,index=False)print(f'✓{basename}')print(f'批量转换完成:{len(csv_files)}个文件')你的数据可能来自不同部门,每个部门一个Excel。
defmerge_excel_files(folder,output_path):"""合并同一文件夹下所有xlsx文件(结构相同)"""all_dfs=[]forfileinos.listdir(folder):iffile.endswith('.xlsx')andnotfile.startswith('~'):file_path=os.path.join(folder,file)df=pd.read_excel(file_path)df['来源文件']=file# 加个标记列all_dfs.append(df)merged=pd.concat(all_dfs,ignore_index=True)merged.to_excel(output_path,index=False)print(f'合并完成:{len(all_dfs)}个文件 →{len(merged)}行')defmerge_by_common_field(folder,common_field,output_path):"""按共同字段合并不同结构的Excel"""merged=Noneforfileinos.listdir(folder):iffile.endswith('.xlsx'):df=pd.read_excel(os.path.join(folder,file))# 确保共同字段存在ifcommon_fieldnotindf.columns:print(f'⚠{file}缺少字段{common_field},跳过')continueifmergedisNone:merged=dfelse:merged=merged.merge(df,on=common_field,how='outer')ifmergedisnotNone:merged.to_excel(output_path,index=False)print(f'合并完成:按{common_field}关联')TEMU店群矩阵自动化运营核价报活动
同步不是"跑一次就完事"的操作,它需要保障机制。
同步完成后的数据量是否对得上?
src_count=len(source_df)dest_count=pd.read_excel(dest_path).shape[0]ifsrc_count!=dest_count:print(f'⚠ 数据量不一致!源{src_count}→ 目标{dest_count}')else:print(f'✓ 数据量一致:{src_count}条')同一个同步脚本,跑两次不应该产生重复数据。
使用if_exists='replace'(全量覆盖)天然是幂等的。增量同步需要在写入前检查是否已存在。
如果写Excel时中途出错,应该保留旧版本不要覆盖:
importtempfiledefsafe_write_excel(df,path):"""安全写入:先写临时文件,成功后再替换"""tmp_path=path+'.tmp'df.to_excel(tmp_path,index=False)os.replace(tmp_path,path)# 原子替换跨平台数据同步,底层就是三个动作:读 → 转 → 写。
Excel、SQLite、飞书、CSV之间的六对组合,掌握好"读"和"写"两端的方法,中间的"转"用pandas搞定。
同步不等于复制——要有数据校验、增量策略、失败保护。
让数据自己流动起来,而不是你手动搬运。
内容标签:#影刀RPA #数据同步 #Excel #飞书 #SQLite #pandas
作者:林焱
系列:影刀RPA进阶教程系列——让数据在系统间自由流动