2026年电子工资条平台价格深度对比:壹人事、蚂蚁、悦享、用友、橙子,谁最省钱?
2026/6/11 19:46:10
数据采集最怕两件事:重复采集和全量重跑。
采集了 5000 条数据,跑完发现有 2000 条是重复的。或者流程崩了,只能把全部数据重新跑一遍,跑完发现数据翻倍了。
这篇文章讲去重和增量采集的实战方案。
| 层面 | 机制 | 适用场景 |
|---|---|---|
| 采集前去重 | 记录已采集的 ID,跳过重复 | 翻页采集、定时增量 |
| 采集后去重 | Pandasdrop_duplicates | 一次性的全量采集 |
| 入库去重 | 数据库 UNIQUE 约束、INSERT IGNORE | 有数据库的项目 |
最佳实践:三层都用。采集前过滤是最省资源的,采集后清洗是最后一道防线。
在采集循环里维护一个"已采集 ID 集合",每次判断。
拼多多店群自动化上架方案
# 用 Python set 实现采集前去重已采集ID=set()# 存为全局变量或流程参数defshould_collect(item_id):"""判断是否应该采集这条数据"""ifitem_idin已采集ID:returnFalse已采集ID.add(item_id)returnTrue# 在采集循环中使用遍历商品列表:商品ID=获取元素文本("商品ID元素")ifnotshould_collect(商品ID):continue# 跳过重复# 正常采集逻辑名称=获取元素文本("商品名称")价格=获取元素文本("商品价格")写入行数据(结果表,[商品ID,名称,价格])set 的优点:查找是 O(1),5000 条数据去重和 50 条一样快。
set 的缺点:只在内存里,流程重启后就丢了。如果要做跨次运行的增量去重,需要用文件。
importos HISTORY_FILE=r"D:\采集记录\已采集ID.txt"defload_collected_ids():"""从文件加载已采集的 ID 集合"""ifnotos.path.exists(HISTORY_FILE):returnset()withopen(HISTORY_FILE,"r",encoding="utf-8")asf:ids=[line.strip()forlineinfifline.strip()]returnset(ids)defsave_collected_id(item_id):"""追加一个 ID 到文件"""withopen(HISTORY_FILE,"a",encoding="utf-8")asf:f.write(f"{item_id}\n")# 流程开始时加载已采集ID=load_collected_ids()print(f"已加载{len(已采集ID)}条历史记录")# 采集循环中遍历商品列表:商品ID=获取元素文本()if商品IDin已采集ID:continue采集商品数据()已采集ID.add(商品ID)save_collected_id(商品ID)importpandasaspd df=pd.read_excel(r"D:\采集数据_原始.xlsx")# 打印去重前统计print(f"去重前:{len(df)}条")# 按单个字段去重(保留第一条)df=df.drop_duplicates(subset=["商品ID"],keep="first")# 按多个字段组合去重df=df.drop_duplicates(subset=["商品ID","采集时间"],keep="last")# 删除所有完全重复的行df=df.drop_duplicates()print(f"去重后:{len(df)}条")# 保存df.to_excel(r"D:\采集数据_去重后.xlsx",index=False)keep参数含义:
"first"→ 保留第一次出现的(推荐)"last"→ 保留最后一次出现的False→ 全删(一个不留,慎用)全量采集效率低,特别是数据量大的时候。增量采集是新老数据对比,只取新增的。
如果数据源有时间字段(上架时间、更新时间),只采集今天更新的。
importdatetime today=datetime.date.today().strftime("%Y-%m-%d")# 在搜索或筛选中限定时间范围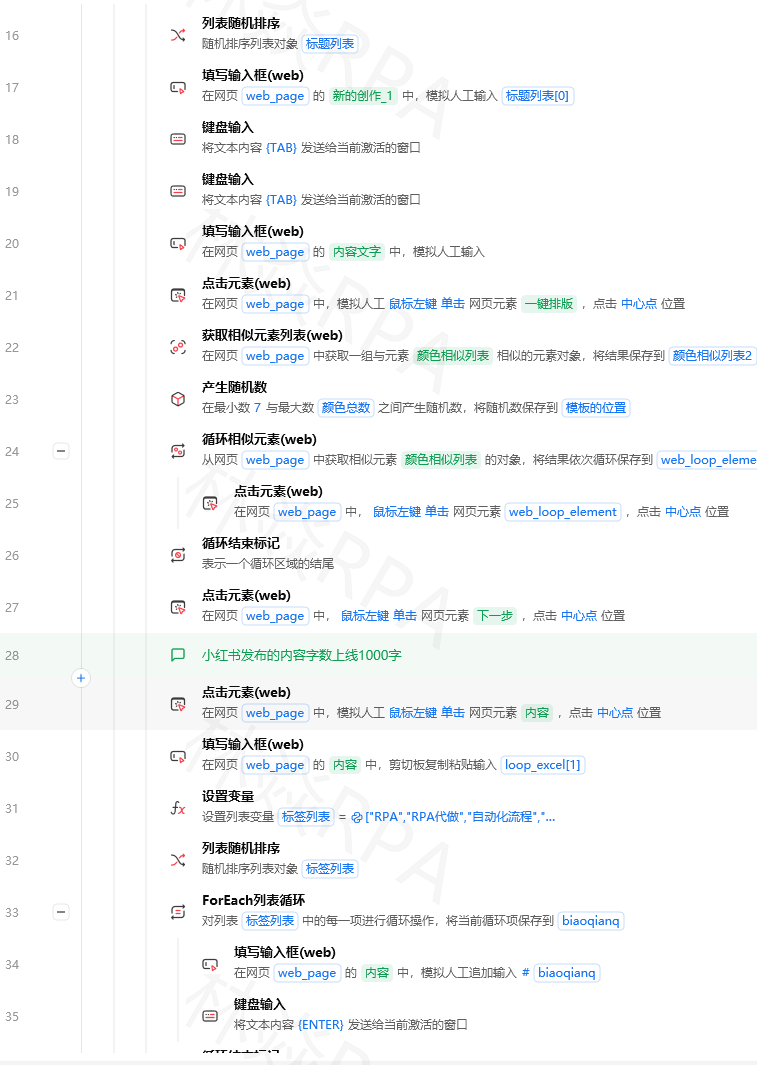选择下拉项("时间筛选","今天")# 或在 API 参数中加时间过滤# 1. 读取历史数据的所有 ID历史数据=pd.read_excel(r"D:\采集历史.xlsx")历史ID集=set(历史数据["商品ID"].astype(str))# 2. 采集新数据新数据=[]# 本次采集的结果遍历商品列表:商品ID=获取元素文本()if商品IDin历史ID集:continue# 已存在,跳过采集一条商品数据 → 新数据.append(结果)# 3. 新数据追加到历史文件iflen(新数据)>0:新数据df=pd.DataFrame(新数据)新数据df.to_excel(r"D:\采集历史.xlsx",mode="a",# 追加模式header=False,# 不加标题行index=False)print(f"本次新增:{len(新数据)}条,累计:{len(历史ID集)+len(新数据)}条")TEMU店群如何管理运营?
标题差不多但有一个标点不同,怎么去重?
fromdifflibimportSequenceMatcherdefis_similar(a,b,threshold=0.85):"""判断两个字符串是否相似"""returnSequenceMatcher(None,a,b).ratio()>threshold# 示例is_similar("韩版气质连衣裙","韩版 气质 连衣裙")# Trueis_similar("韩版连衣裙","男士运动短袖T恤")# False模糊去重只适合数据量小的时候(几百条),多了性能很差。大量数据建议用ID 精确匹配 + 人工抽查。
1. 加载历史数据 → 获取已有 ID 集合 2. 开始采集 → 每条检查 ID 是否已有 3. 已有 → 跳过;没有 → 采集并加入集合 4. 每采集 N 条(比如 50 条)→ 写一次文件(防中断丢数据) 5.  6. 采集结束 → 统计新增数量 → 通知# 增量采集的防中断策略BUFFER_SIZE=50# 每 50 条写一次buffer=[]已保存ID=load_collected_ids()foriteminitems:ifitem.idin已保存ID:continuedata=collect_one(item)buffer.append(data)iflen(buffer)>=BUFFER_SIZE:# 写入文件pd.DataFrame(buffer).to_csv(r"D:\增量数据.csv",mode="a",header=False,index=False)# 更新 ID 文件fordinbuffer:save_collected_id(d["商品ID"])已保存ID.add(d["商品ID"])print(f"已写入{len(buffer)}条,累计{len(已保存ID)}条")buffer=[]# 最后一批不足 BUFFER_SIZE 的数据ifbuffer:pd.DataFrame(buffer).to_csv(r"D:\增量数据.csv",mode="a",header=False,index=False)fordinbuffer:save_collected_id(d["商品ID"])ID 不稳定:有些平台商品 ID 会变(编辑后重新生成),依赖 ID 去重可能失效。观察一下你采集的平台 ID 到底稳不稳。
去重后数据量对不上:drop_duplicates不会告诉你具体删了哪些重复行。排查时建议在去重前导出原始数据的重复项统计。
增量 ID 文件过大:采集了 10 万条后,TXT 文件里有 10 万行 ID,加载会变慢。改用set存内存,文件只保留最近 N 天的,历史 ID 转存数据库。
mode="a"追加 Excel 的坑:Pandas 追加 Excel 需要openpyxl引擎,且目标文件必须存在。如果文件不存在要先新建。
作者:林焱
本文为《影刀RPA学习手册》系列文章之一,内容源于实操经验的整理与分享。